总所周知,目前的大模型文本生成已达到了一个非常出色的水平,但是还是有一些存在的问题:
1.如果我们想生成比较长的文章,大模型的生成限制并不能满足我们这一点
(大模型本身有输出上限限制,不过这也受限于你的推理卡等级和内存大小,理论上可以调至无限大)
2.如果我们想以章节生成文章,大模型的上下文接收也有限,也不能满足
(在生成后面章节的内容时,很可能会超出输入上限,导致前面章节的记忆丢失,丧失文章完整性,导致生成的文本质量很差)
如果我们想要保证文本质量,那么必须进行人工干预(手动输入一些关键信息给大模型学习)
这些一键式方法都挺难行得通的,那有其他一键式方法吗?
接下来从一个个问题出发,找到一键式的终极方案
问题一:大模型上下文限制
如果上下文受到限制了,那把上文的关键信息提取出来不就可以了?
所以我们可以采用TF-IDF+BERT的双重验证进行信息提取
再使用SQL实现这些信息的保存(SQL数据调用和查找快)
TF-IDF是什么
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TF-IDF算法的不足之处:
(1)没有考虑特征词的位置因素对文本的区分度,词条出现在文档的不同位置时,对区分度的贡献大小是不一样的。
(2)按照传统TF-IDF,往往一些生僻词的IDF(反文档频率)会比较高、因此这些生僻词常会被误认为是文档关键词。
(3)传统TF-IDF中的IDF部分只考虑了特征词与它出现的文本数之间的关系,而忽略了特征项在一个类别中不同的类别间的分布情况。
(4)对于文档中出现次数较少的重要人名、地名信息提取效果不佳。
这里有一篇对该方法的改进算法论文TF-IWF
BERT的作用
BERT会将输入的句子进行深层的语义理解,将句子内的动名词和人物或场景进行剥离,输出一个包含多维的向量
所以我们需要一些信息抽取模型进行输出再处理,以达到真正的关键信息提取
import spacy
from transformers import pipeline
nlp = spacy.load("zh_core_web_trf")
relation_extractor = pipeline("relation-extraction", model="bert-base-chinese")
def analyze_text(text):
# 实体识别
doc = nlp(text)
entities = [(ent.text, ent.label_) for ent in doc.ents]
# 关系抽取
relations = relation_extractor(text,
candidate_labels=["保护", "敌对", "合作"])
# 动作分析
verbs = [token.lemma_ for token in doc if token.pos_ == "VERB"]
return {
"entities": entities,
"relations": relations,
"actions": verbs
}
text = "林动将青檀护在身后,冷冷地盯着对面的王雷"
result = analyze_text(text)
print(result)
通过这种方法可以输出人物间关系的json数据
{
"entities": [
["林动", "PERSON"],
["青檀", "PERSON"],
["王雷", "PERSON"]
],
"relations": [
{
"relation": "保护",
"subject": "林动",
"object": "青檀",
"confidence": 0.89
},
{
"relation": "敌对",
"subject": "林动",
"object": "王雷",
"confidence": 0.78
}
],
"actions": ["护", "盯"]
}
并且可以使用GAT图注意网络,用图连接构建人物之间的关系
SQL作用
CREATE TABLE context_index (
id INTEGER PRIMARY KEY,
keyword TEXT NOT NULL, -- 关键词
position_start INT, -- 起始位置
position_end INT, -- 结束位置
embedding BLOB, -- 768维向量
context_type TEXT, -- 类型:角色/场景/物品
FOREIGN KEY (doc_id) REFERENCES chunks(id)
);
问题二:文本的断点生成
我们无法保证机器能一直使用保持不断的训练,所以需要断点的技术来保存所训练的参数
所以可以将每次训练结束的结果保存为一个会话,通过git保存断点,所以可以进行回滚等操作
为优化储存空间,只保存模型参数和上下文关键信息,以及生成到的位置(保存未完成的句子等)
# 目录结构设计 checkpoints/ ├── session_12345/ # 会话ID │ ├── model/ # 模型相关状态 │ │ ├── adapter.safetensors # LoRA适配器权重 │ │ ├── optimizer.pt # 优化器状态 │ │ └── config.json # 模型配置 │ ├── runtime/ # 运行时状态 │ │ ├── kv_cache/ # 分块KV缓存 │ │ │ ├── layer0.pt │ │ │ └── layer1.pt │ │ └── position.bin # 位置编码状态 │ ├── context/ # 上下文存储 │ │ ├── chunk_001.msgpack # 文本分块 │ │ └── index.sqlite # 上下文索引 └── manifest.json # 全局检查点清单
增量更新机制:只增加修改的记录,减少存储空间
输入文本
"林修在青云宗后山练剑时,意外触发上古剑阵,获得了一柄通体漆黑的玄铁重剑"
1. **上下文索引**:
- 关键词:青云宗(地点) | 玄铁重剑(物品) | 上古剑阵(事件)
- 关联段落:第3章第5节
2. **角色更新**:
- 林修:
* 新增物品:玄铁重剑(重量: 72斤, 材质: 陨铁)
* 修为变化:剑意境界+1
* 地点记录:后山剑阵
3. **场景记录**:
- 地点:青云宗后山
- 特征:隐藏的上古剑阵
- 时间线:主线剧情第15天
问题三:文本之间的衔接问题
我们现在将关键信息保存了,并且设置了生成断点,那我们该怎么样才能保证文本之间的逻辑性呢?
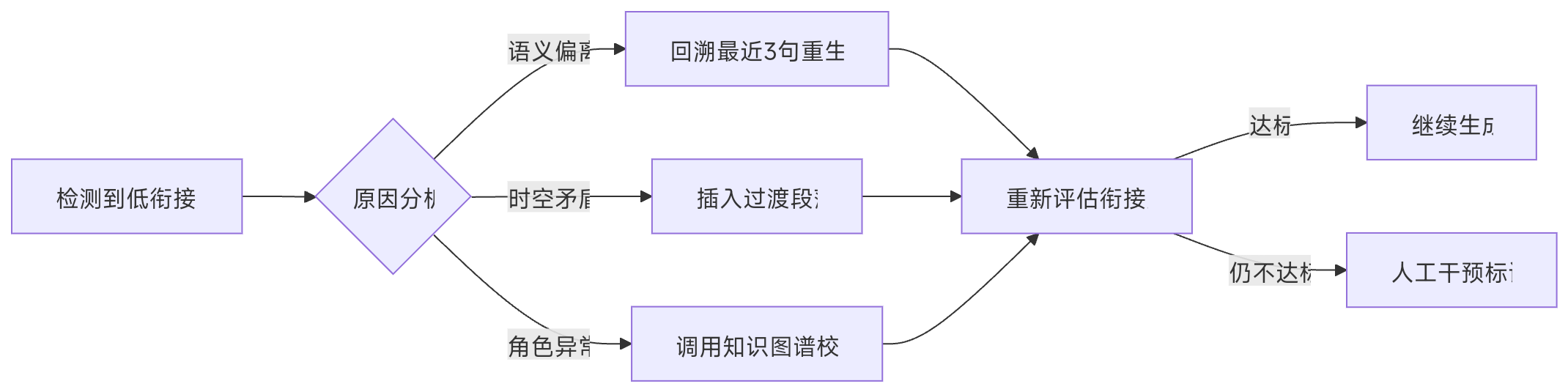
所以我们可以使用查找关键词逻辑冲突和语义是否连贯等方法验证是否出现了不一致
以语义连贯度 实体一致性 时序合理度 过渡自然度为标准进行判断
关键技术有Dygie++和Raft
Dygie++通过对捕获了局部信息(句内)和全局信息(跨句)的text spans进行枚举、精炼、打分,处理命名实体识别(NER)、关系抽取(RE)和事件抽取(EE)共3种信息抽取(IE)任务
Raft实现了状态同步(将不同的数据分给节点,得到多数节点通过就同意该状态)

